Abstract
Robotic manipulation tasks often span over long horizons and encapsulate multiple subtasks with different skills. Learning policies directly from long-horizon demonstrations is challenging without intermediate keyframes guidance and corresponding skill annotations. Existing approaches for keyframe identification often struggle to offer reliable decomposition for low accuracy and fail to provide semantic relevance between keyframes and skills. For this, we propose a unified Keyframe Identifier and Skill Anotator(KISA) that utilizes pretrained visual-language representations for precise and interpretable decomposition of unlabeled demonstrations. Specifically, we develop a simple yet effective temporal enhancement module that enriches frame-level representations with expanded receptive fields to capture semantic dynamics at the video level. We further propose coarse contrastive learning and fine-grained monotonic encouragement to enhance the alignment between visual representations from keyframes and language representations from skills. The experimental results across three benchmarks demonstrate that KISA outperforms competitive baselines in terms of accuracy and interpretability of keyframe identification. Moreover, KISA exhibits robust generalization capabilities and the flexibility to incorporate various pretrained representations.
Motivation Example
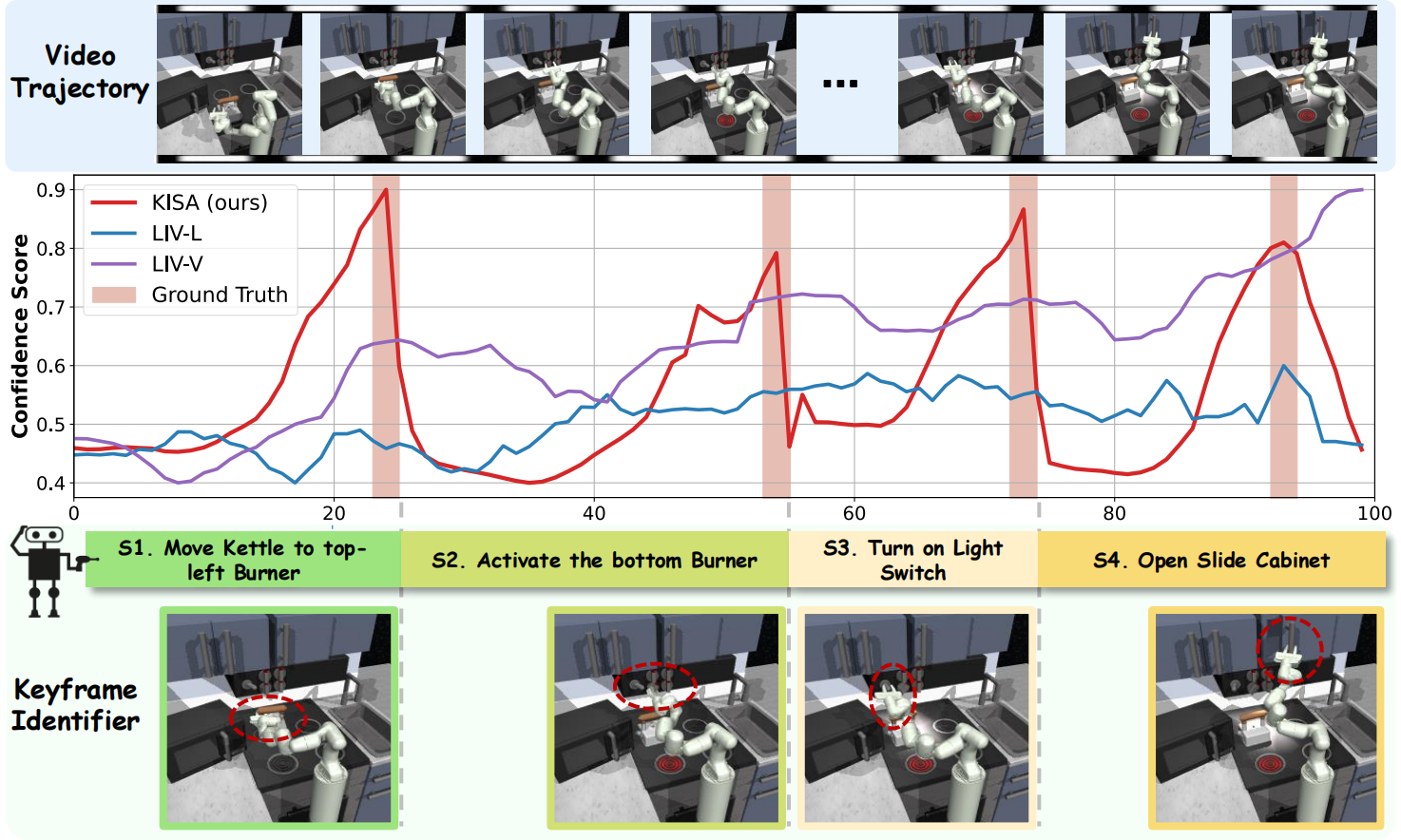
Overview of Keyframe Identification.
Both goal image similarity(LIV-I) and skill language similarity(LIV-L) struggle to stand out at keyframes.
KISA can exhibit conspicuous peaks near groundtruth boundaries for accurate keyframe identification.
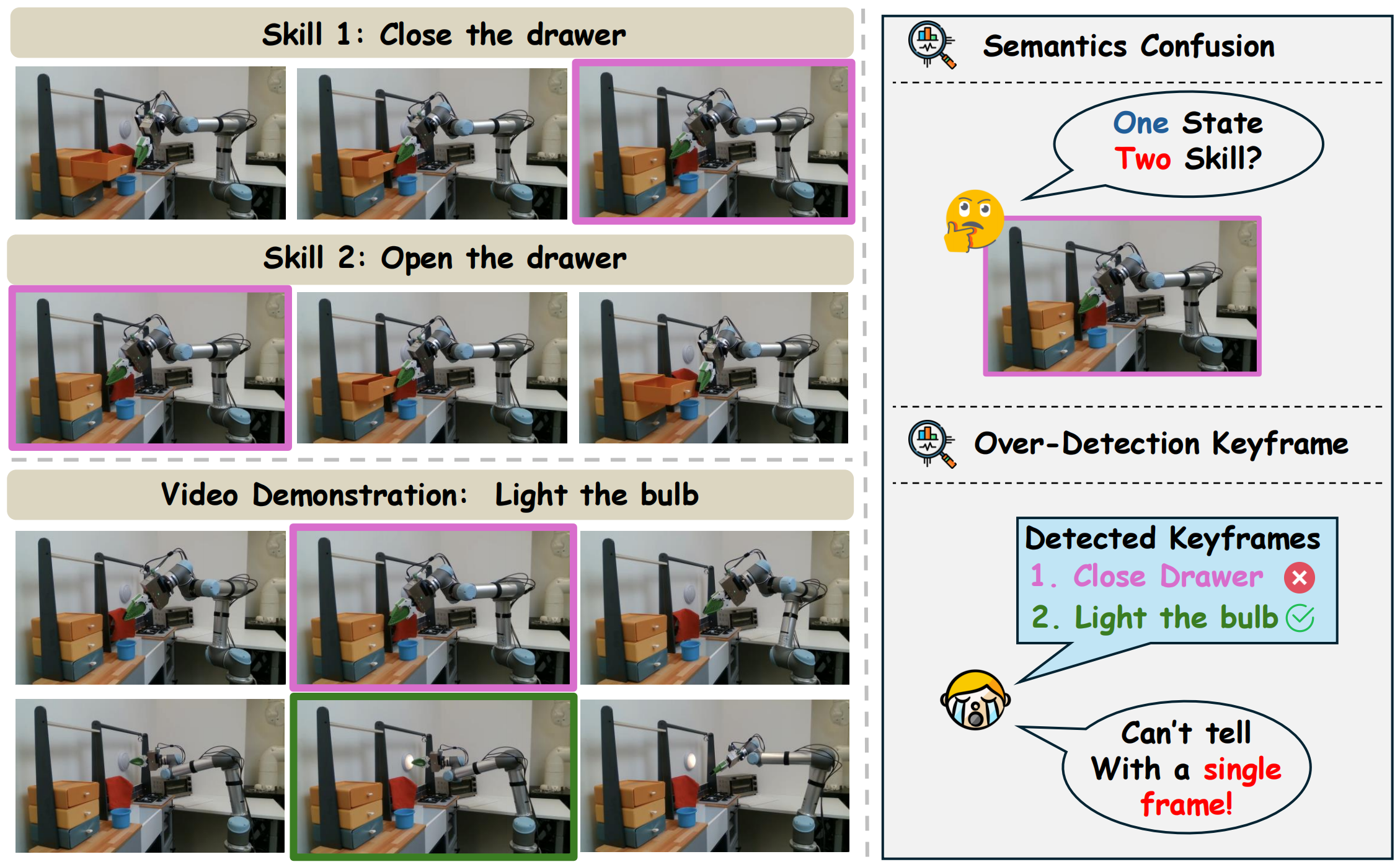
Motivation Example.
Without historical context for semantic action cognition, two visually similar frames from different skills can confuse the alignment. Furthermore, the
representation might overfit the alignment between isolated frames and skills, leading to over-identification or false-identification.
Method
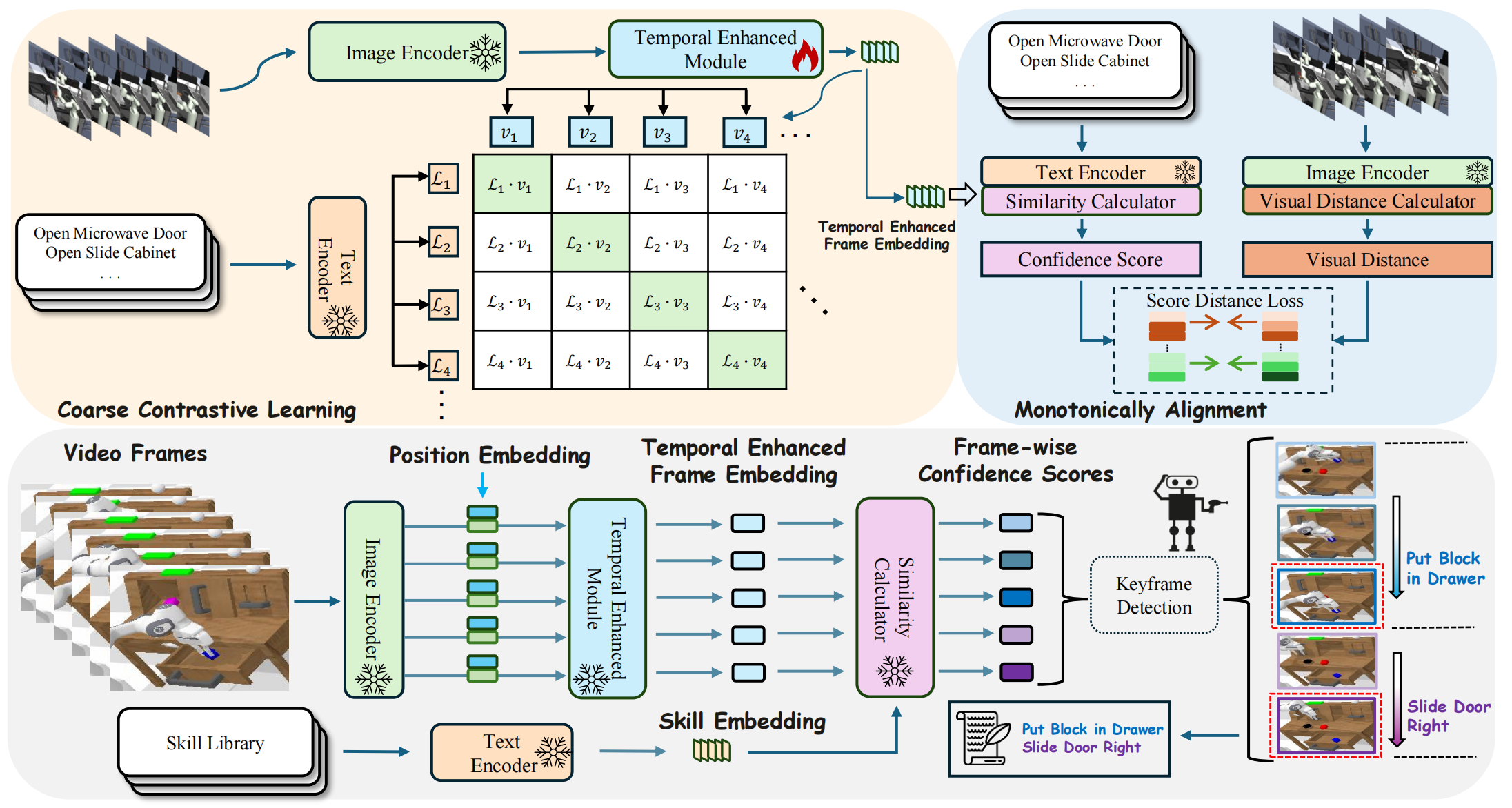
Overview framework of KISA.
KISA first leverages a simple yet effective temporal enhancement module upon the pre-trained vision-language representation to
obtain the video-level representation for each frame. During training, the alignment involves two branches: Inter-skill: we
design coarse history-aware contrastive learning via constructing hard negative samples with mismatched historical contexts and incorrect skills.
Intra-skill we additionally fine-grained monotonic alignment to encourage the capture of skill-aware progress within the sub-task, and prevent representation collapse to highly similarity within the same skill.
Qualitative Results
Visualization of Keyframe Identification
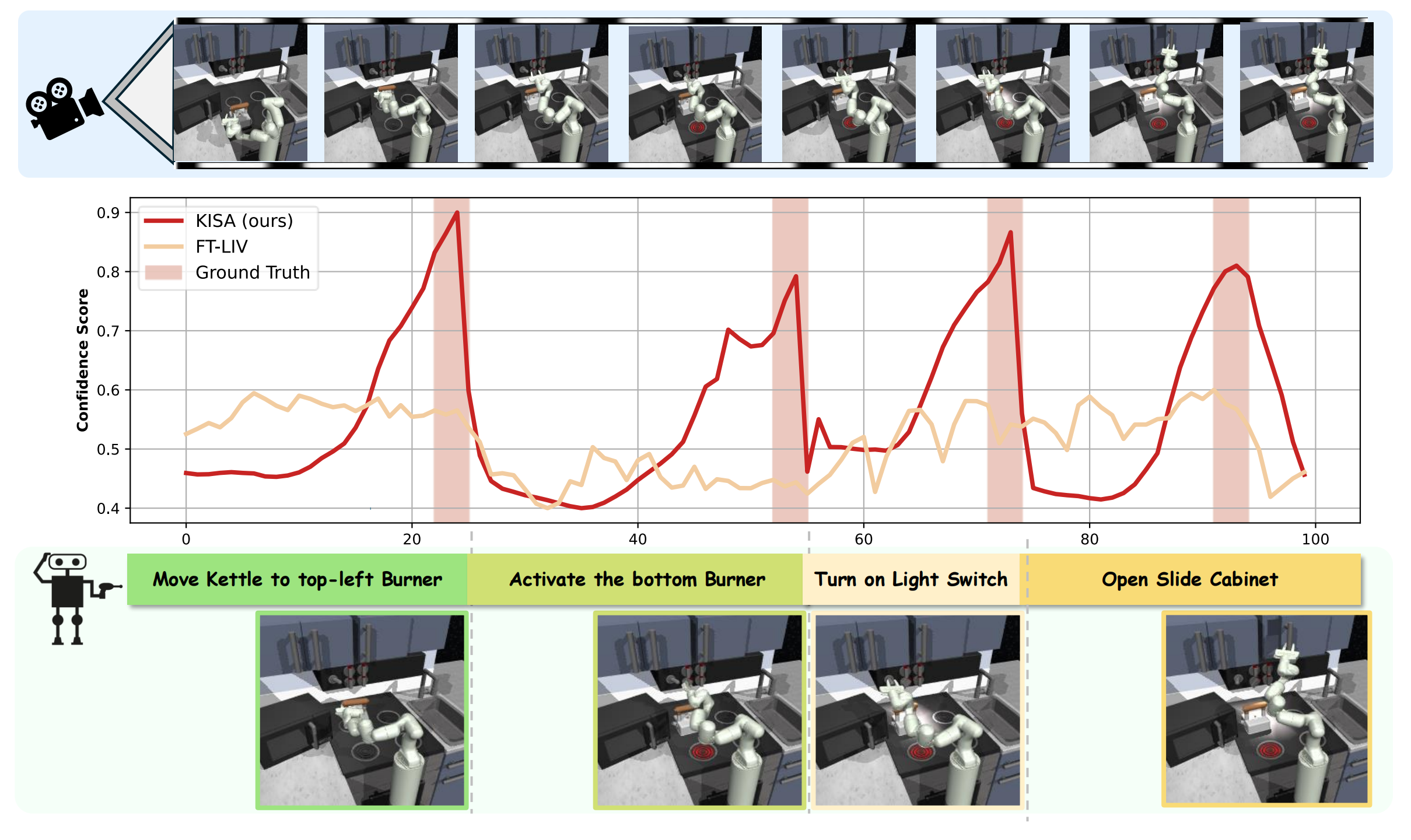
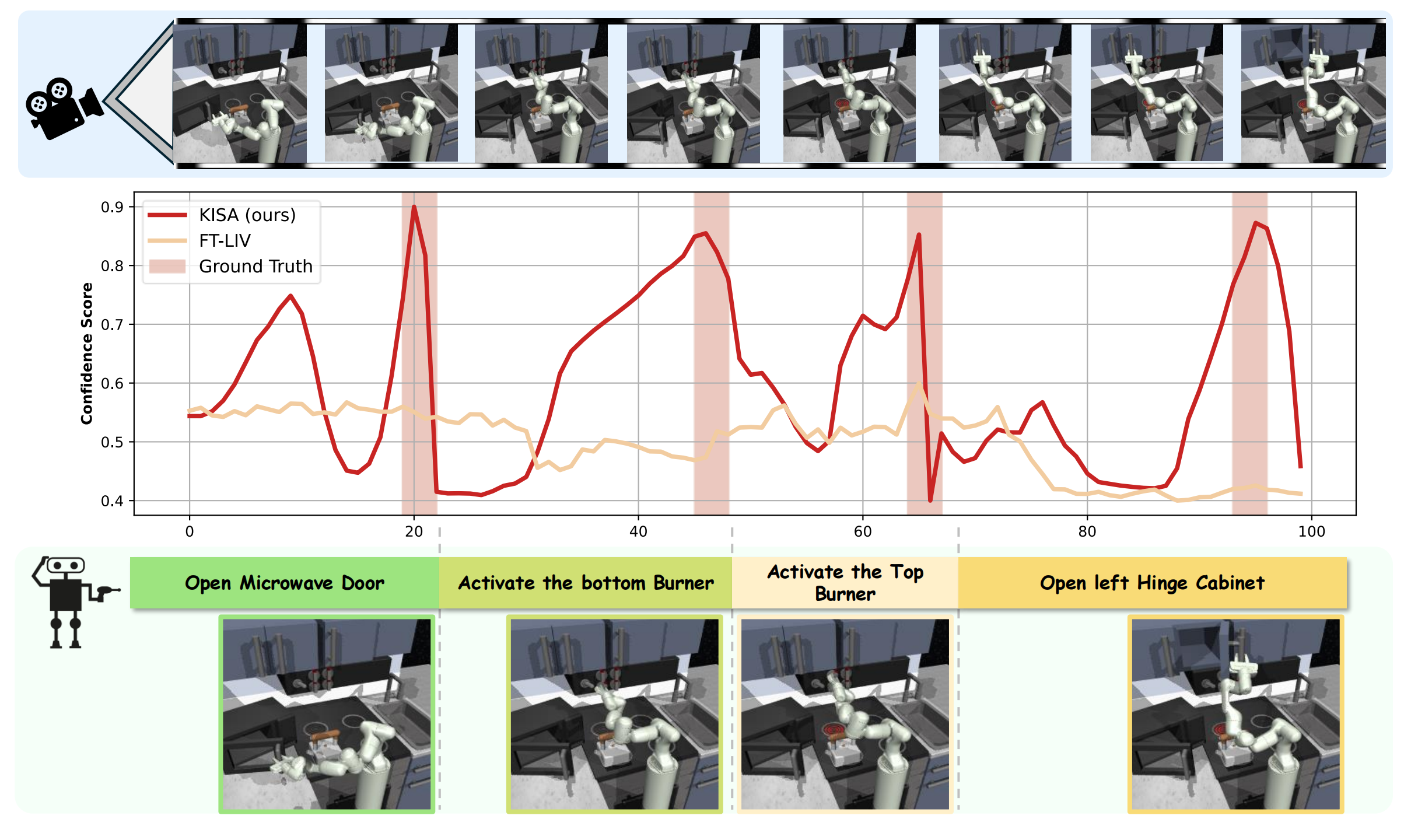
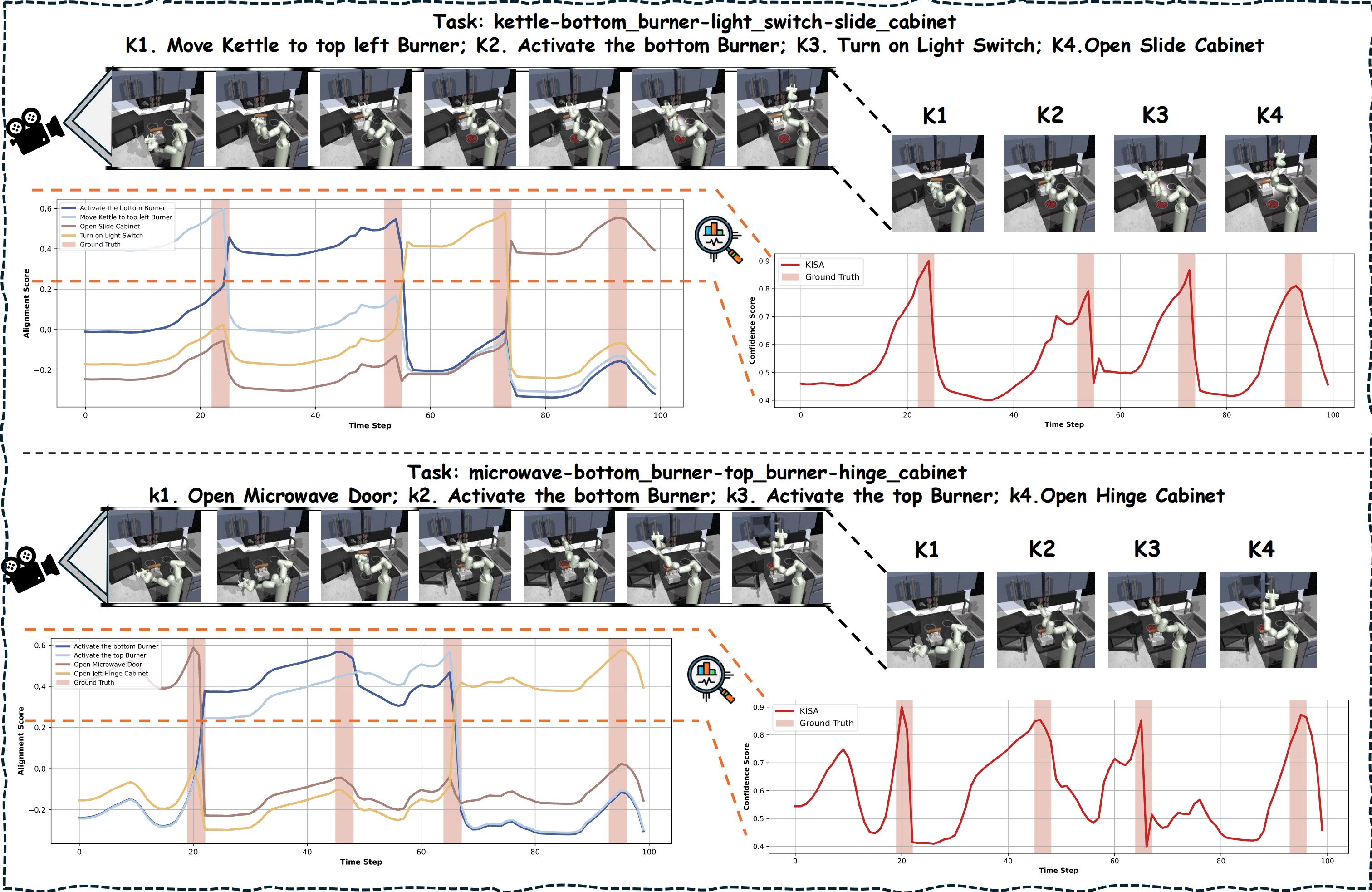
The Visualizaton of KISA in FrankaKitchen:
(left)Move the kettle to the top-left burner, activate the bottom burner, turn on the light switch, and open the slide cabinet.
(right)Open the Microwave Door, activate the bottom burner, activate the top burner and Open the left Hinge Cabinet.
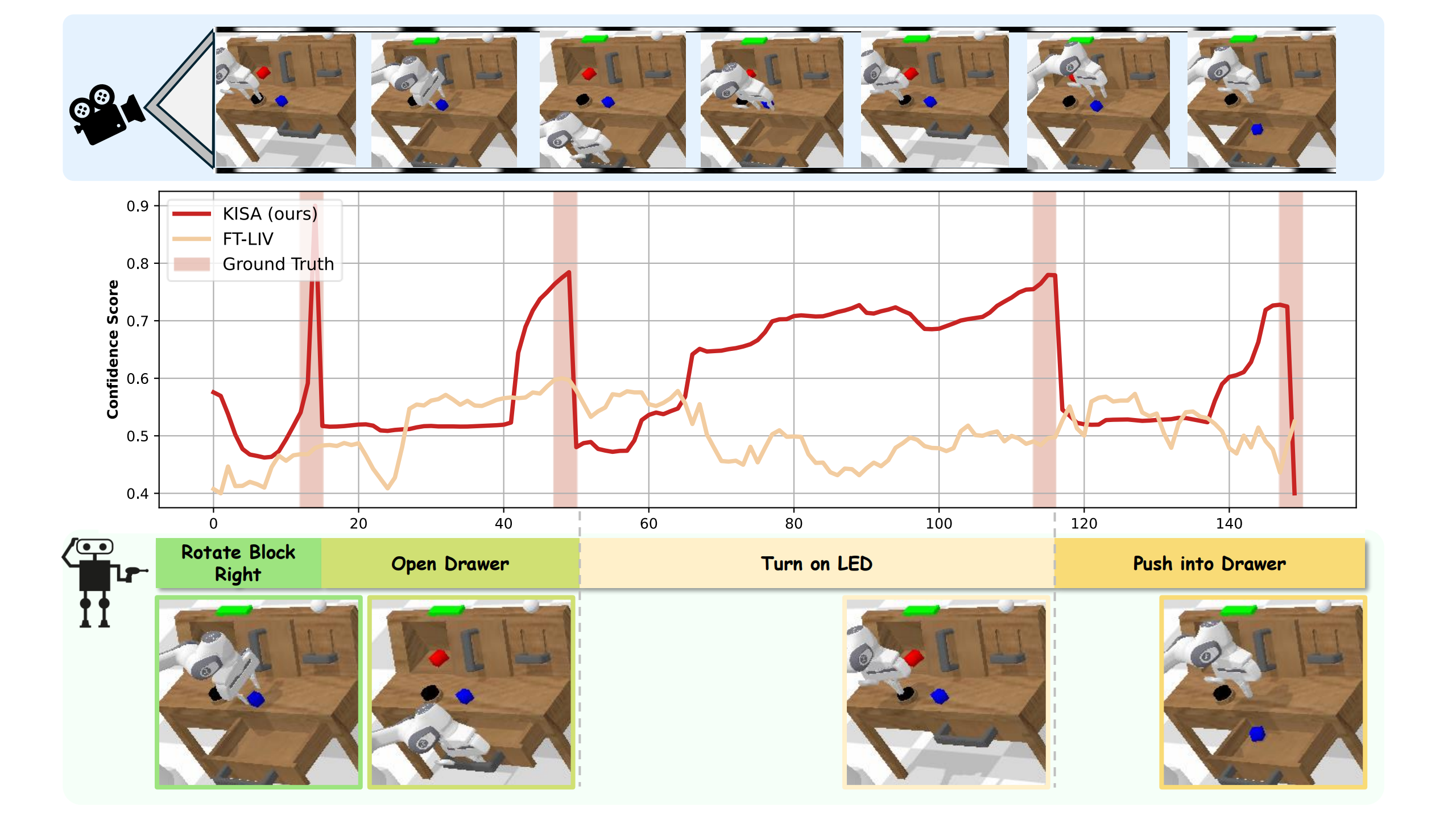
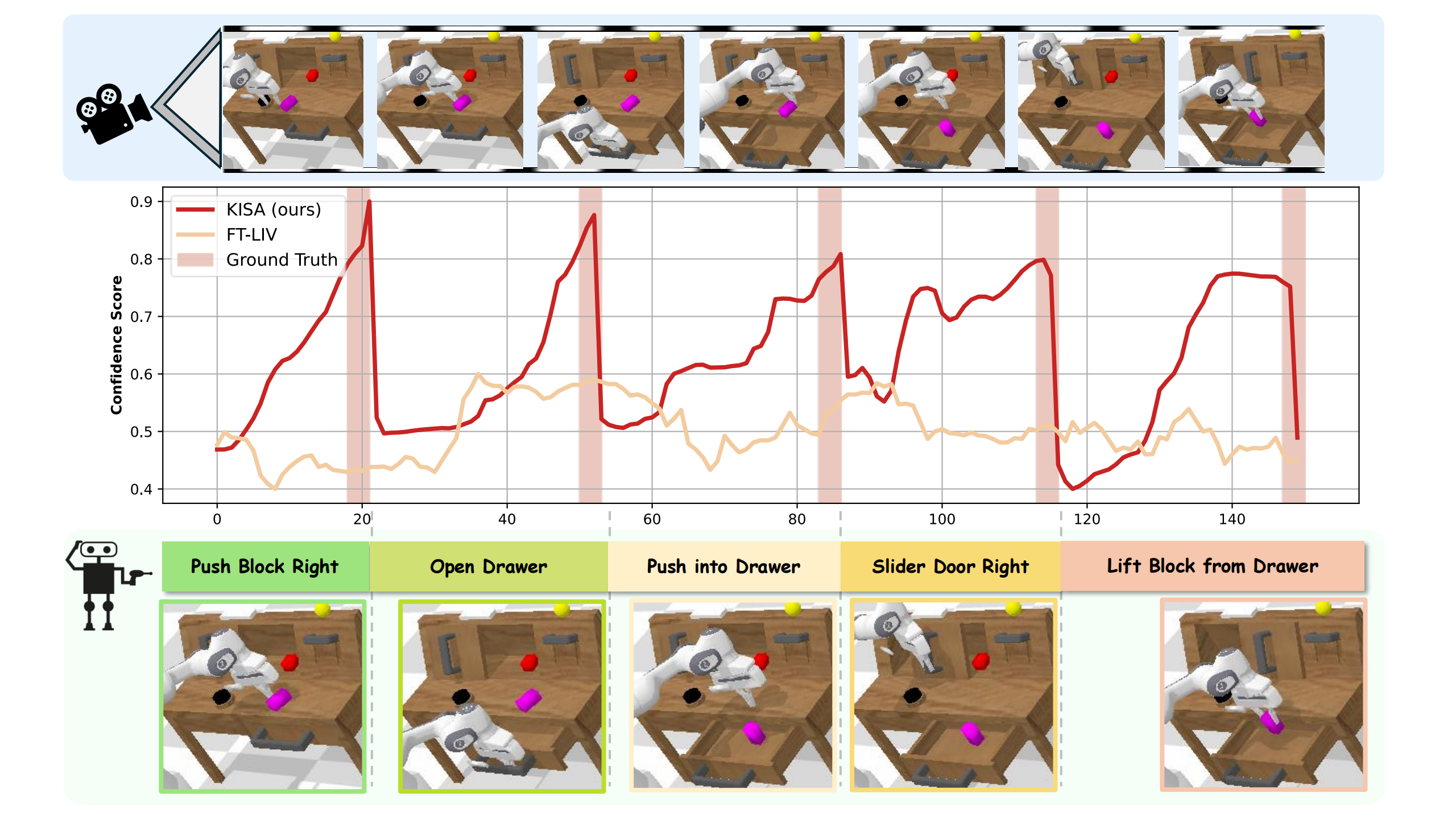
The Visualizaton of KISA in CALVIN:
(left)Rotate Block Right, Open Drawer, Turn on LED and Push into Drawer.
(right)Rotate Block Right, Open Drawer, Push in Drawer, Slide Door Right and Lift Block from Drawer.
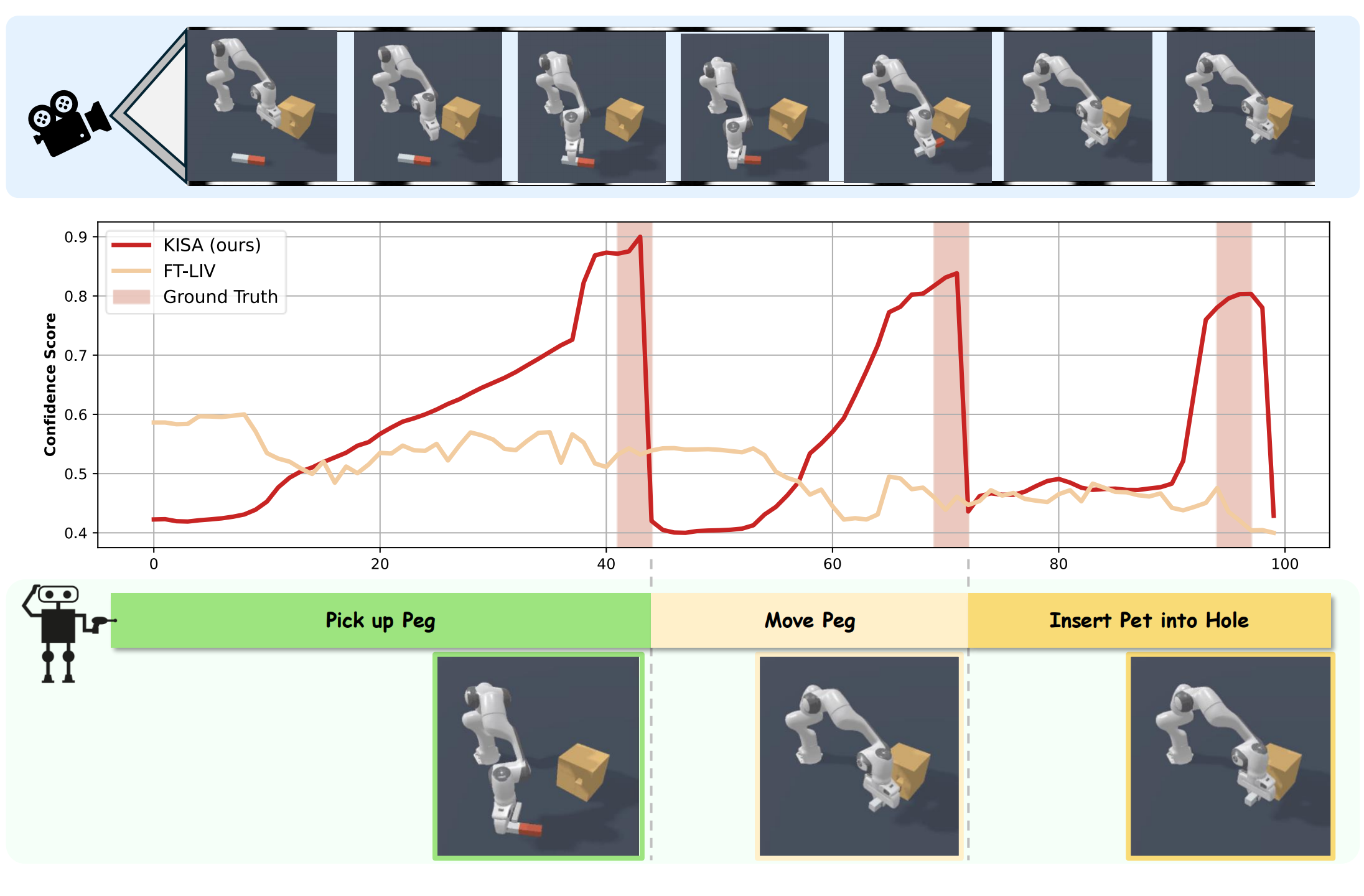
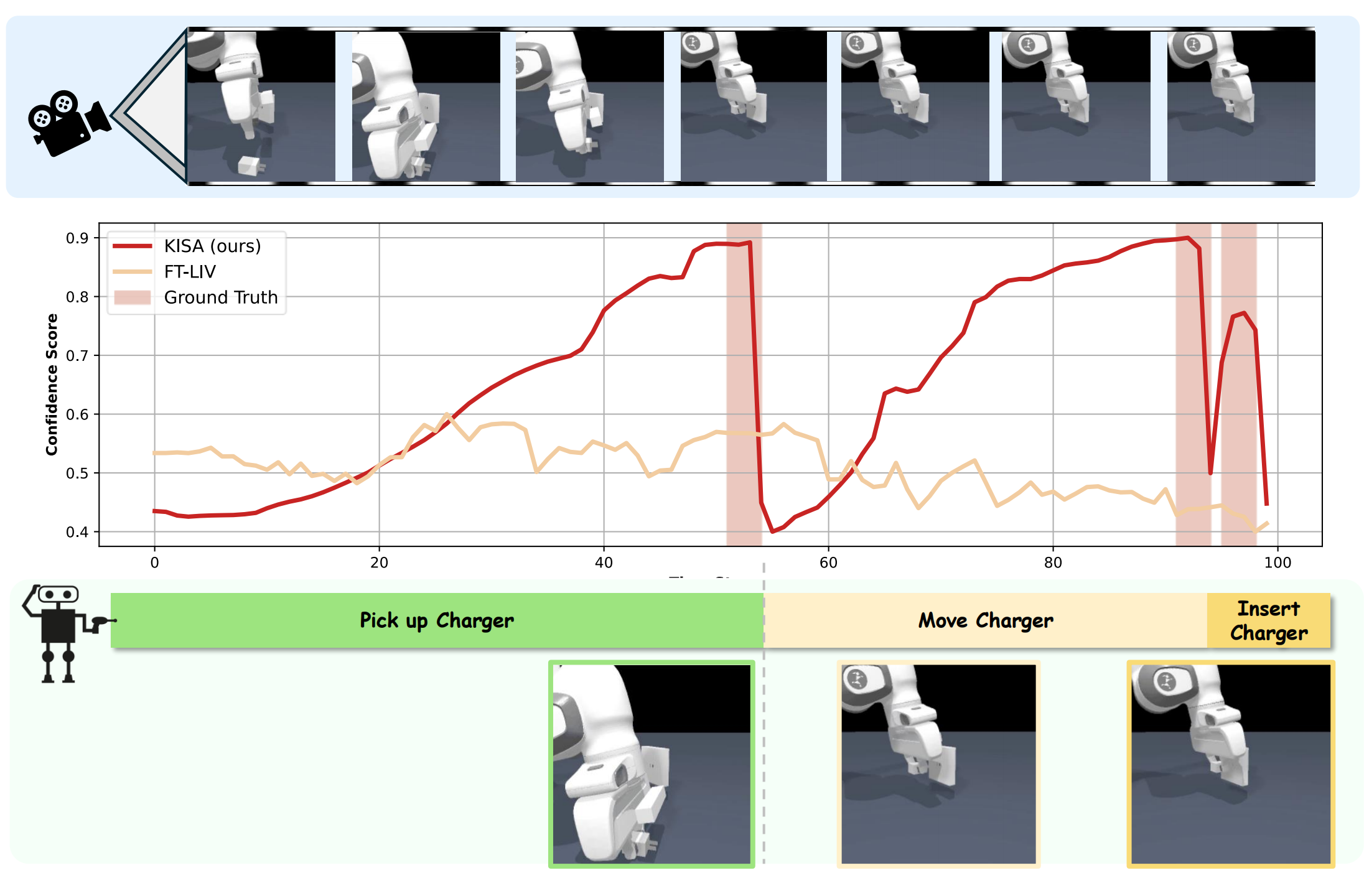
The Visualizaton of KISA in Maniskill2:
(left)Pick up the peg, Move the Peg, and Insert the Peg into the Hole.
(right)Pick up the Charger, Move the Charger, and Insert the Charger into Receptacle.
Confidence Scores for Keyframe Identification
A example of confidence score calculation.
For each step, the confidence score is the maximum similarity between video-level representation and language representation from skills.
The Heatmap of Alignment Score between Skills and Frames
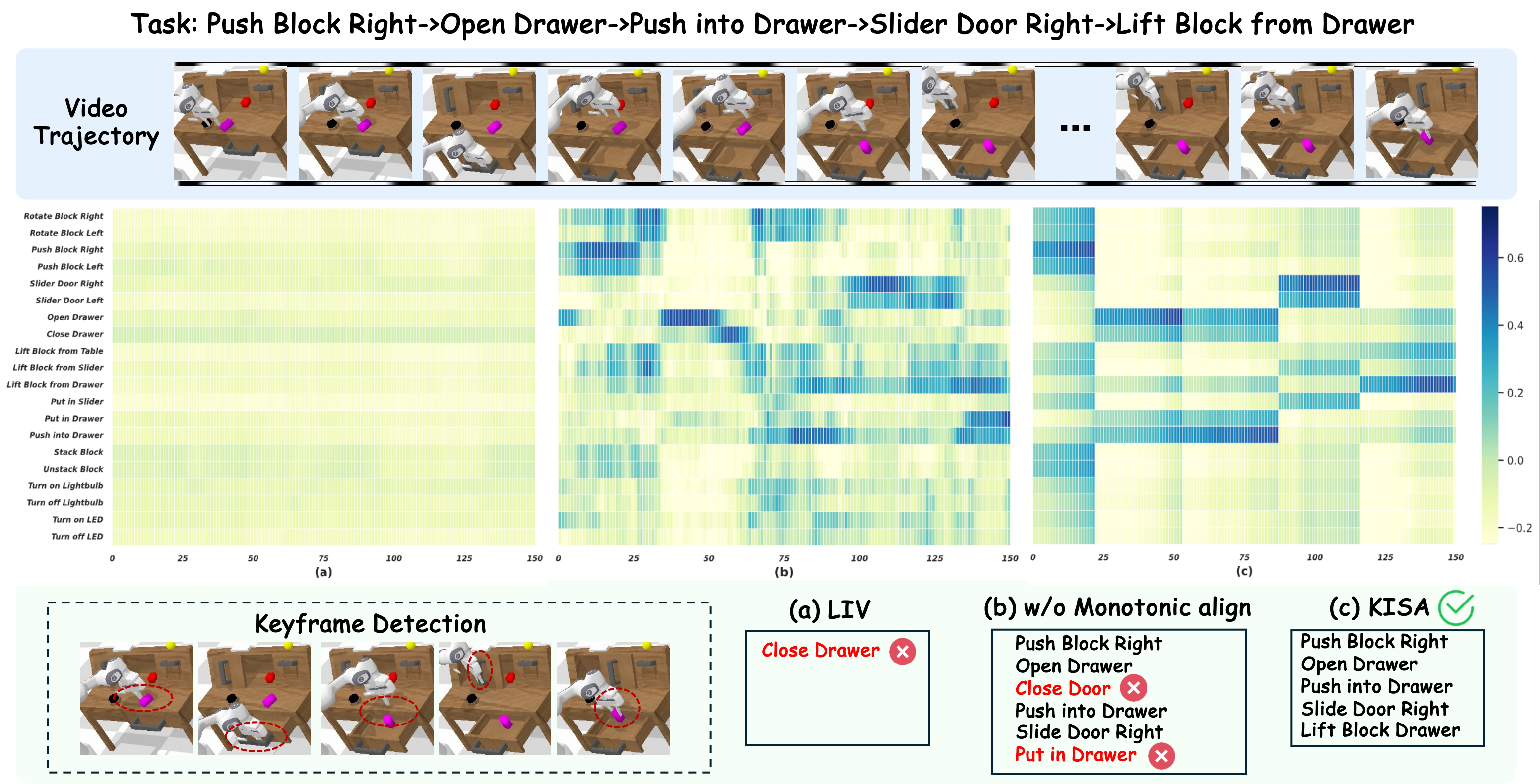
The heatmap between skills and frames from a long-horizon demonstration example on CALVIN. The comparisons between
LIV (a), KISA w/o monotonic alignment (b) and KISA (c).
Word Clouds

World Clouds:
To visually summarize the key aspects covered by the diverse manipulation skills in ManiSkill2, CALVIN, and FrankaKitchen
benchmarks, we created the word clouds. We now tokenize the instruction and for each skill code used in the
trajectory, record all the tokens from the language instruction. Once we have this mapping from skills to tokens, we can plot
heat maps and word clouds. The predominant terms reflect a heavy focus on interacting with household objects like boxes,
cans, bottles, tools, and tableware. Terms such as ”pick up”, ”move”, ”rotate”, and ”stack” indicate the skills that aim to test
fundamental robot capabilities in grasping, manipulating, and placing common items. The emergence of words depicting
spatial reasoning like ”left/right” and goal configurations highlights skills requiring contextual understanding and mapping
instructions to feasible actions.
t-SNE Visualization
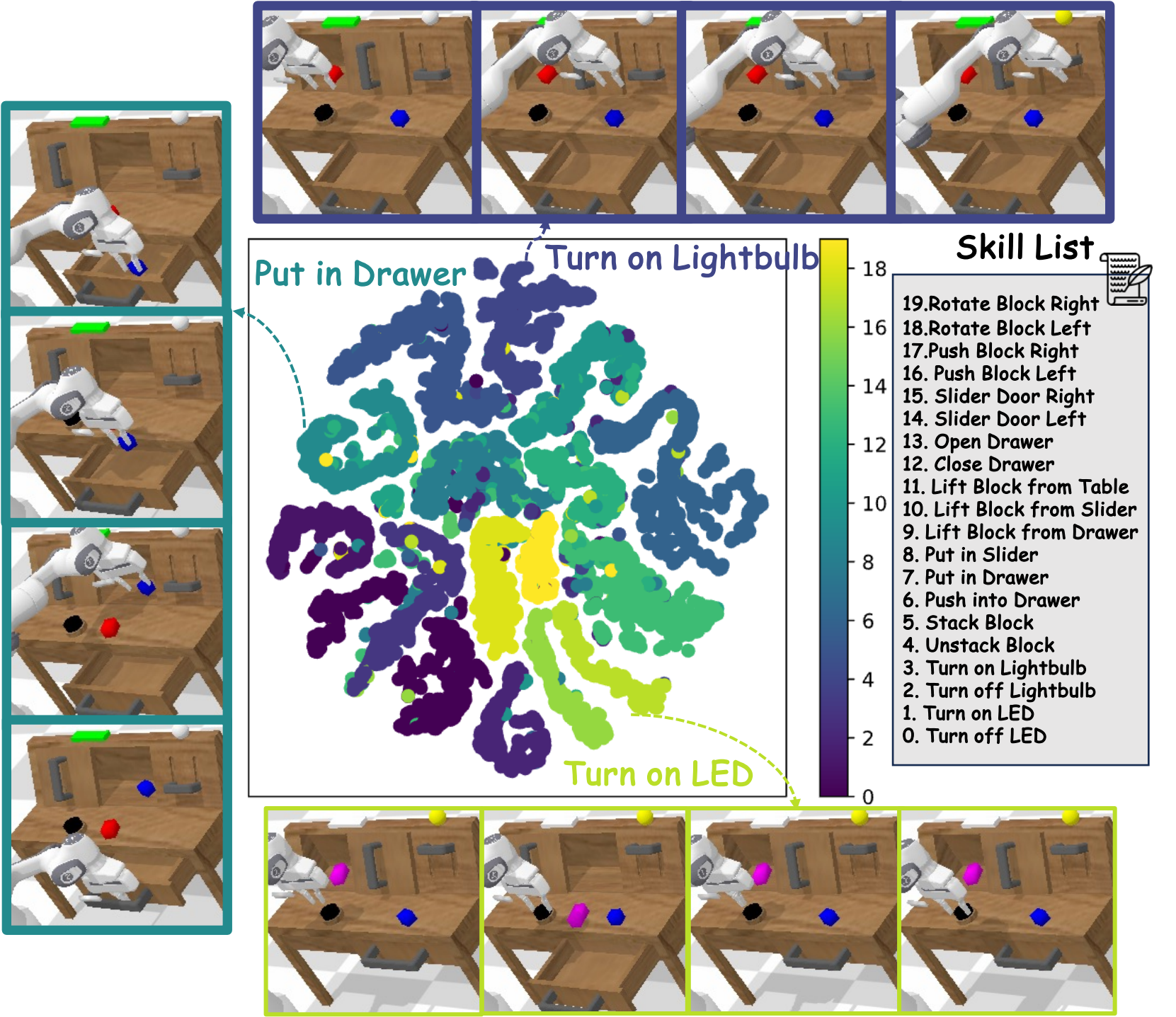
t-SNE Visualization of Skill Space in CALVIN
reveals the relationship between the defined skills based on their visual
dynamics. Each point denotes one skill type, colored by category. The modular relationships indicate promise for the zero-shot
composition of new behaviors by leveraging similarity within the embedding space during policy learning.
Quantitative Results
The evaluation results of keyframe identification
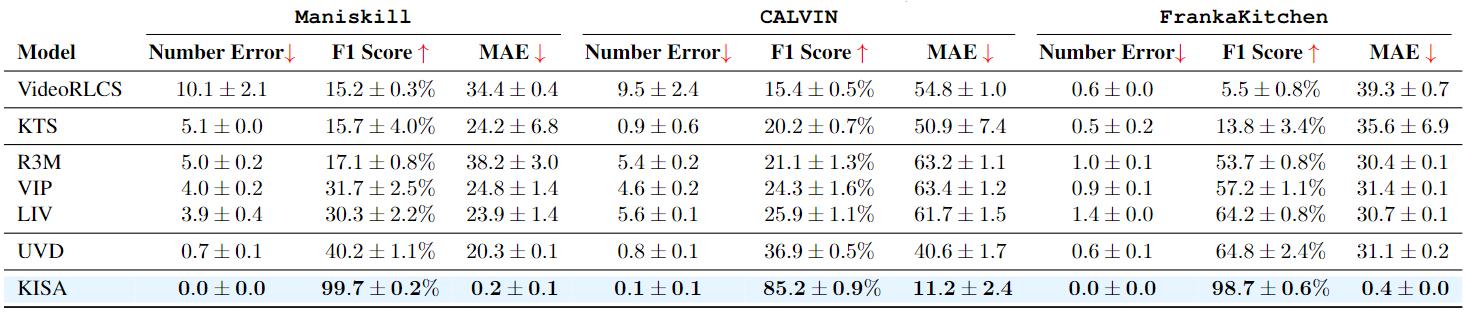
We evaluate several baselines on the collected long-horizon demonstrations dataset with groundtruth skill labels three typical manipulation environments and report the mean and variance across 5 seeds.
KISA significantly outperforms all baselines across three metrics, highlighting its superior ability in keyframe identification.
Reward-driven keyframe extraction methods like VideoRLCS perform the worst among baselines. A potential reason is that the importance of the keyframe for reward prediction decreases when the horizon extends and the visual representation is not exploited.
On the other hand, unsupervised methods like KTS without additional training, which solely relies on the similarity of visual embeddings for clustering, can already achieve a higher accuracy than VideoRLCS.
This provides empirical insight that the visual information has great potential for keyframe identification. Moreover, we directly utilize pretrained robotics representations such as R3M, VIP, and LIV to assess the ability to identify keyframes.
The accuracy improves in the order of R3M, VIP, and LIV, with the latter enjoying more fine-grained representation properties.
The comparisons of skill annotation
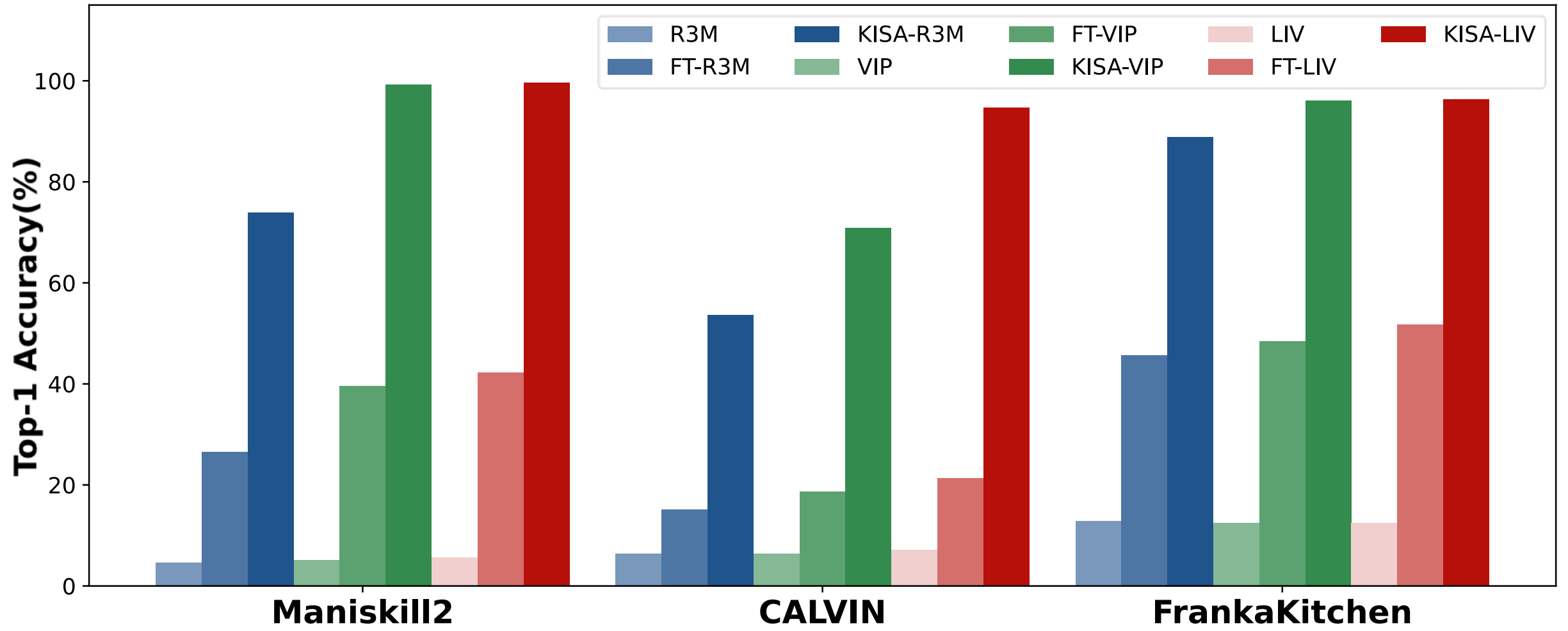
On all three classic robotics representations, the skill annotation accuracy of the `KISA-'
version outperforms that of the `FT-' version, which follows the vanilla alignment technique with static representation.
Zero-shot Results
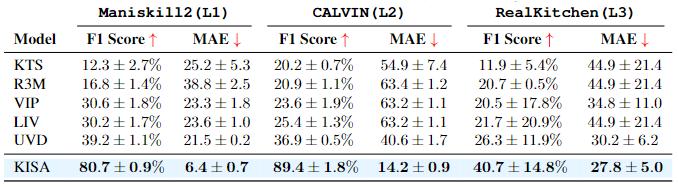
To systematically examine generalization capacities, we establish a 3-level protocol evaluating models on progressively more challenging unseen distributions without additional
training: (L1) Object Generalization: We evaluate L1 genralization on rich manipulation scenes from Maniskill2, with diverse object colors, shapes, numbers, and placements.
(L2) Combinatorial Generalization: We evaluate generalization on CALVIN for novel skill compositions that never appear in training and also examine the accuracy of decomposition in longer horizon cases. (L3) Embodiment Generalization.
Combinatorial Generalization (L2) on CALVIN
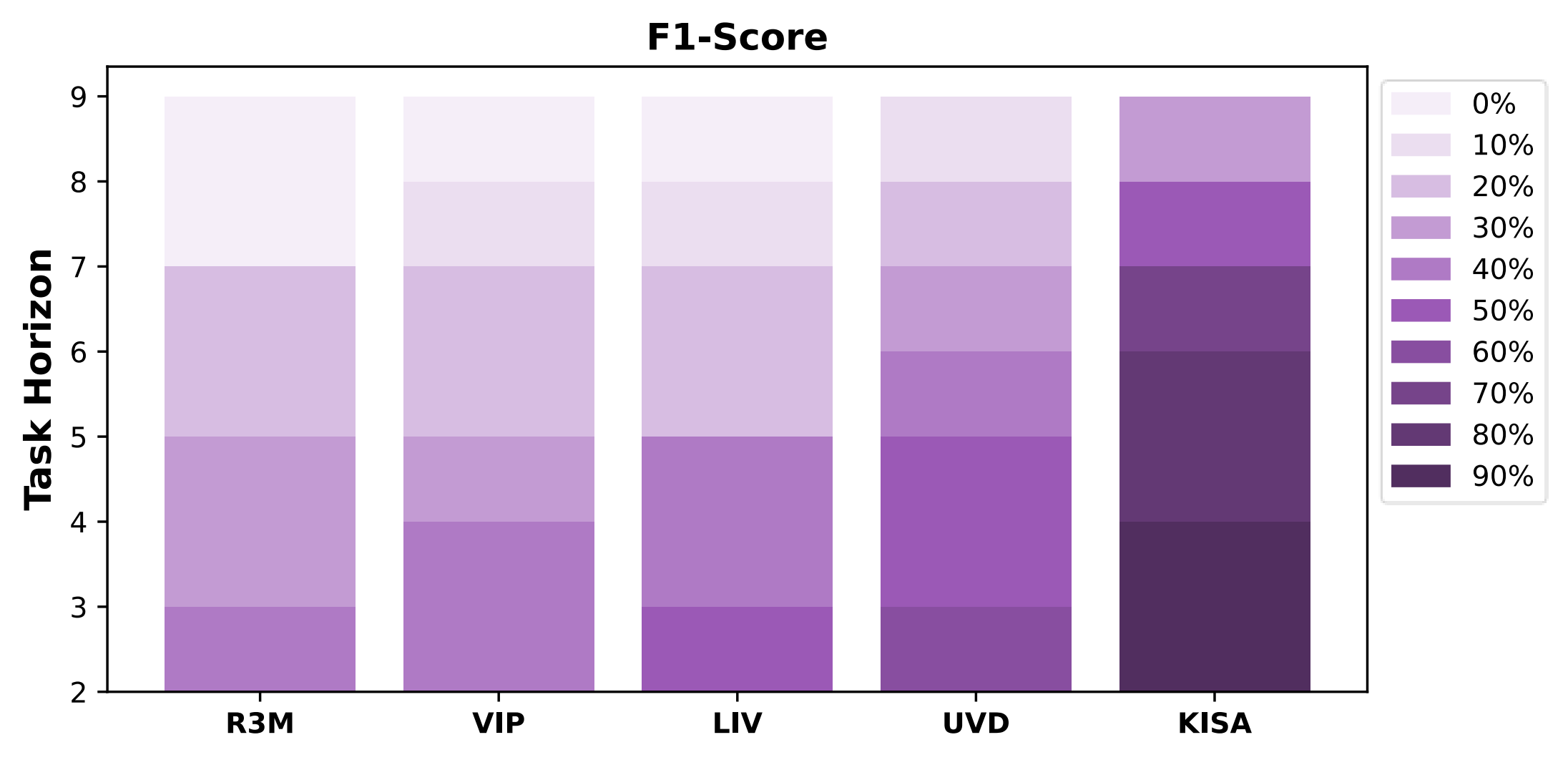
As the horizon extends, the combinatorial generalization ability of the KISA remains significantly stronger than baselines.
This is primarily due to KISA’s ability to integrate historical frames to expand receptive fields, which allows it to better capture long-range skill dynamics beyond isolated
frames. Rather than overfitting to superficial environmental details, KISA focuses on learning on core semantics - reducing dependence on specific configurations or scenes.
Cross Embodiment Generalization (L3)
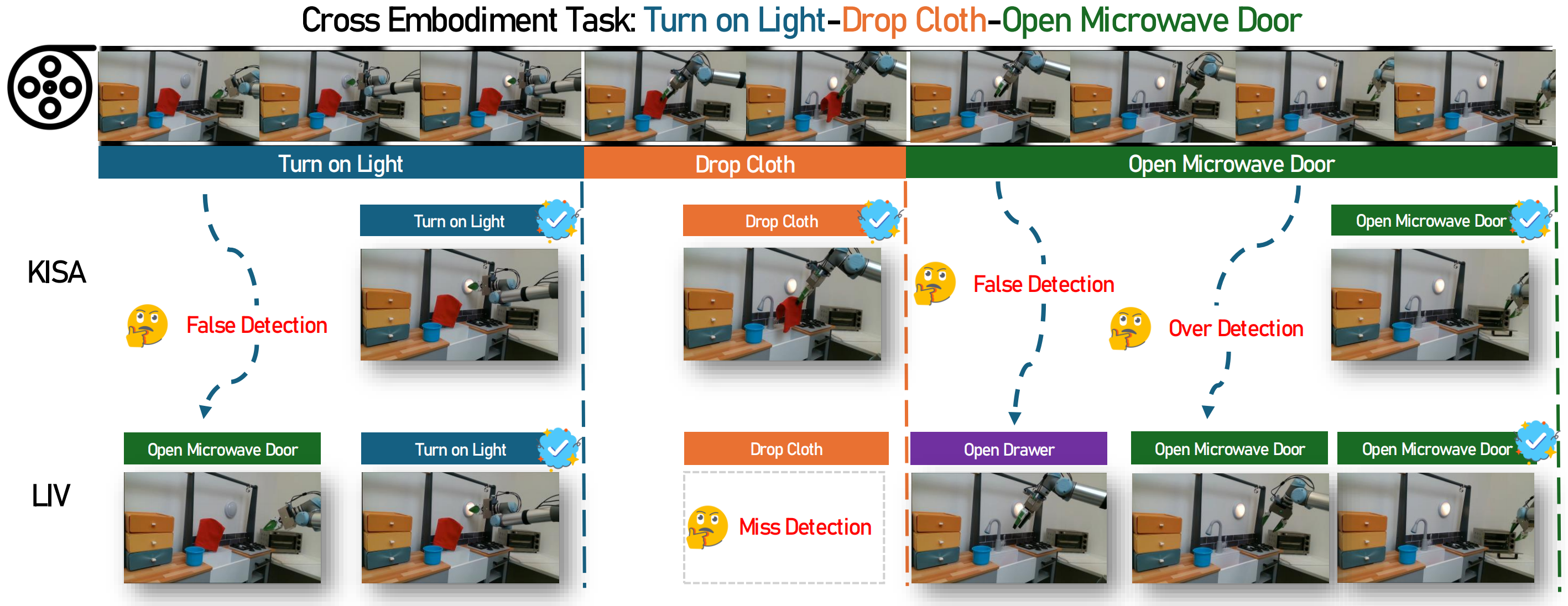
The illustrating example of LIV and KISA for zero-shot generalization from simulators on long-horizon real robotics demonstration datasets.
The Flexibility for Pre-trained Representations
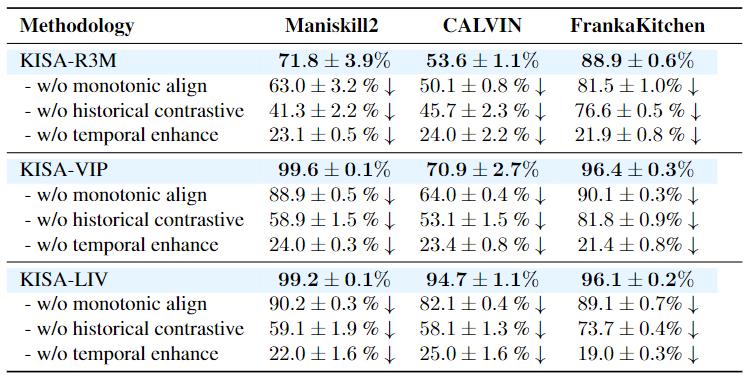
KISA equips static frame-level representations with video-level understanding capability, which is flexible to incorporate with
any existing visual representation backbone. We conduct comprehensive evaluations across R3M, VIP, and LIV through ablations studies of the proposed temporal en-
hancement module, history-aware contrastive learning, and monotonicity alignment components respectively.
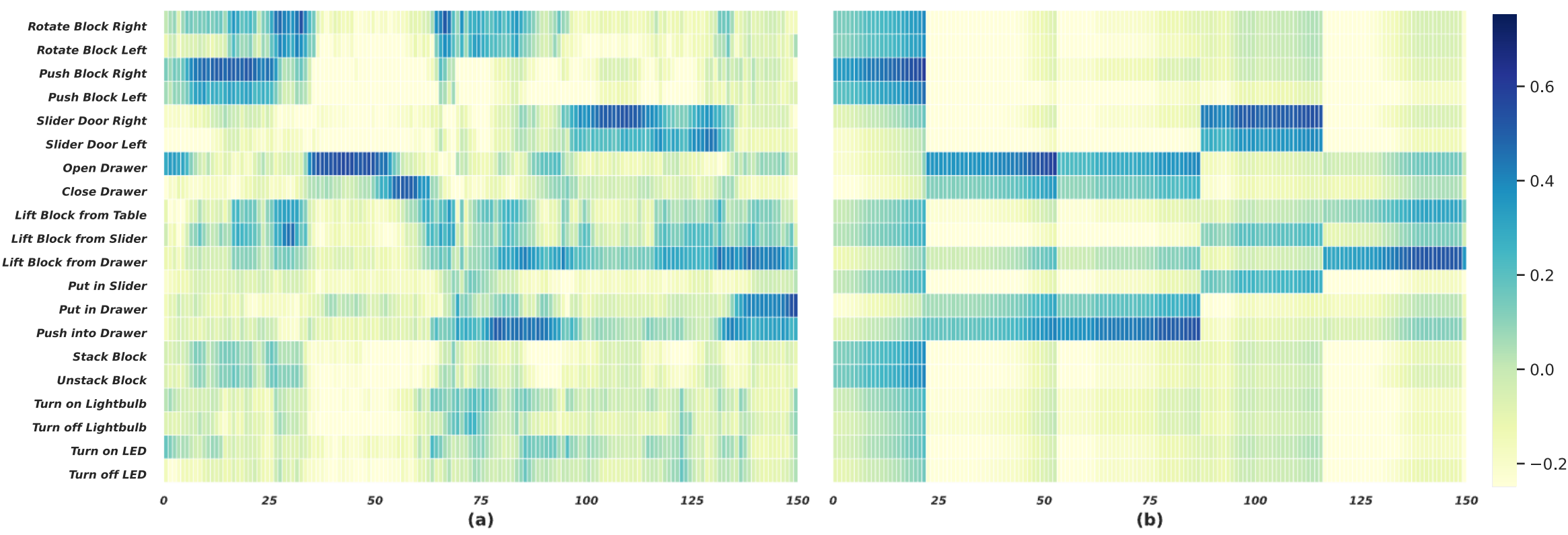
The heatmap between skills and frames from a long-horizon demonstration example on CALVIN.
The comparisons between KISA w/o monotonic alignment (left) and KISA (right).
The Effectiveness for Policy Learning
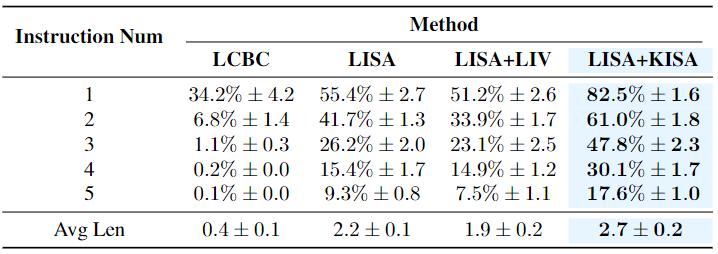
Success rates on CALVIN including LCBC, LISA, and the variation with demonstration annotated by LIV and KISA.
Based on LISA, we compare when provided with privileged information including explicit keyframes and skill annotations to avoid re-discovering skills, while retaining
low-level skill-conditioned policy learning for fair comparisons. Unsurprisingly, LISA+KISA achieves a significant performance improvement with annotated demonstrations, particularly in tasks with longer horizons.
Typical Cases
Success Case
Failure Case
Conclusion
In this paper, we introduce KISA, a unified framework to achieve accurate keyframe identification and skills annotation for long-horizon manipulation demonstrations. We propose a simple yet effective temporal enhanced module that can flexibly equip any existing pre-trained representations with expanded receptive fields to capture long-range semantic dynamics, bridging the gap between static frame-level representation and video-level understanding. We further design coarse contrastive learning and fine-grained monotonic encouragement to enhance the alignment between keyframes and skills. The experiment results demonstrate that KISA achieves more accurate and interpretable keyframe identification than competitive baselines and enjoys the robust zero-shot generalization ability. Furthermore, demonstrations with accurate keyframes and interpretable skills annotated by KISA can significantly facilitate policy learning. We believe that KISA can serve as a reliable tool to accurately annotate robotics demonstrations at a low cost, potentially facilitating the research in robotics community.